AlphaGo Zero三天击败旧版本 比战胜柯洁还厉害的AlphaGo来了
2017-10-19 14:18:00 来源: 凤凰
以前其他版本的AlphaGo,都经过人类知识的训练,它们被告知人类高手如何下棋。而最新发布的AlphaGo Zero使用了更多原理和算法,从0开始,使用随机招式,40天后成为围棋界的绝世高手。真真正正的自学成才。
新的AlphaGo Zero使用了一种全新的强化学习方式,从0基础的神经网络开始,与搜索算法结合,不断进化调整、迭代升级。AlphaGo Zero的不同之处在于:
除了黑白棋子,没有其他人类教给AlphaGo Zero怎么下棋。而之前的AlphaGo包含少量人工设计的特征。
AlphaGo Zero只用了一个神经网络,而不是两个。以前AlphaGo是由“策略网络”和“价值网络”来共同确定如何落子。
AlphaGo Zero依赖神经网络来评估落子位置,而不使用rollouts——这是其他围棋程序使用的快速、随机游戏,用来预测哪一方会获胜。
创新工场AI工程院副院长王咏刚用“大道至简”四个字评价新版的AlphaGo Zero。
上述种种,让AlphaGo Zero异常强大。
“人们一般认为机器学习就是关于大数据和海量计算,但是DeepMind通过AlphaGo Zero的案例发现,算法比计算或者数据可用性更重要”,AlphaGo团队负责人席尔瓦(Dave Silver)介绍说,AlphaGo Zero的计算,比之前的AlphaGo减少了一个数量级。
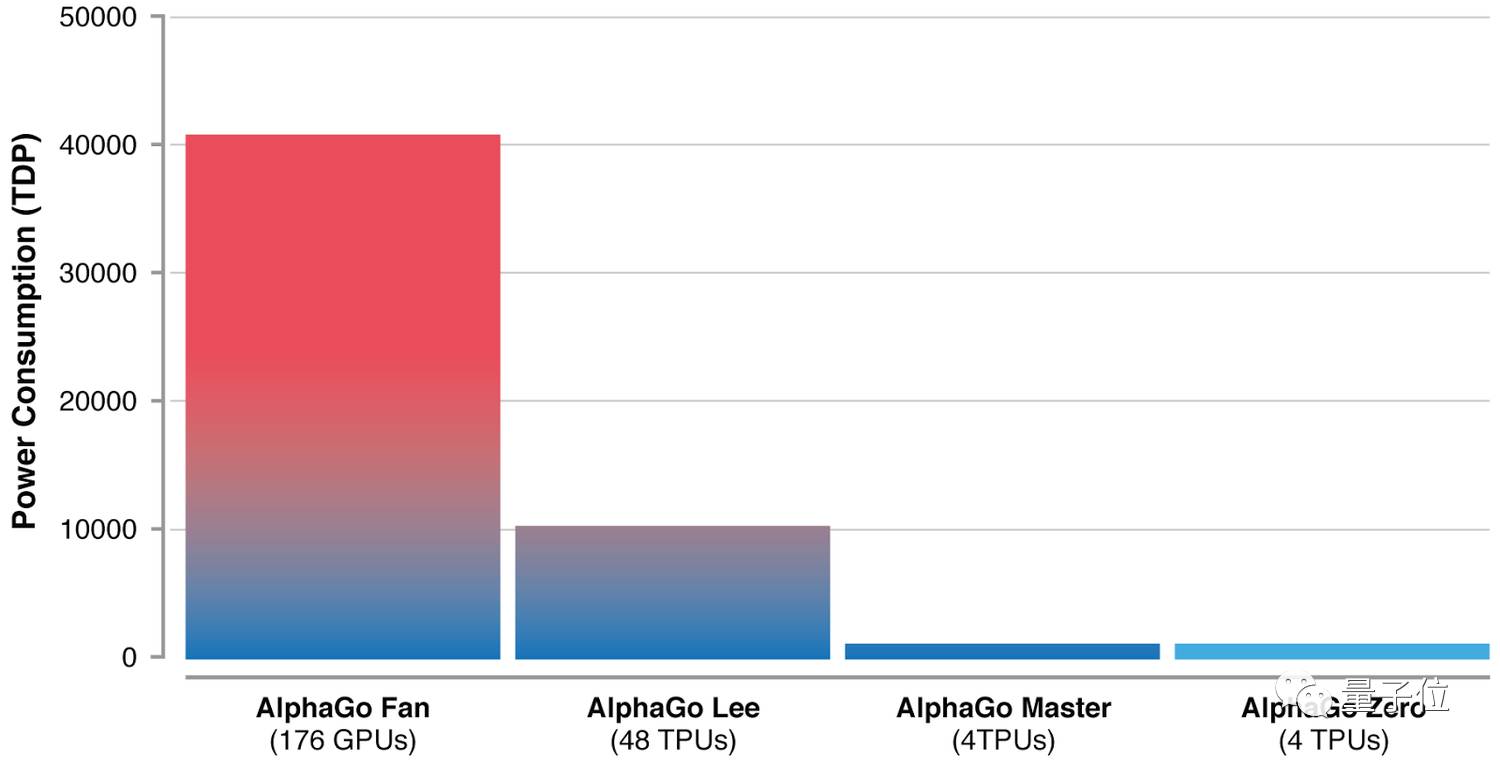
如上图所示,AlphaGo Zero也只用了4个TPU。
AlphaGo Zero到底多厉害,且看官方公布的成绩单:
3小时后,AlphaGo Zero成功入门围棋。
仅仅36小时后,AlphaGo Zero就摸索出所有基本而且重要的围棋知识,以100:0的战绩,碾压了当年击败李世乭的AlphaGo v18版本。






相关推荐
-
《李茂扮太子》预售过千万 马丽常远与你“美丽常伴”
-
《向着明亮那方》扎根中国故事 超越年龄限制的“童年宝藏”
-
苗侨伟《飞虎3》再演“阿sir” 期待有突破自己的机会
-
《东北虎》官宣定档 映照生活中的荒诞与无奈
-
女心理师小文扮演者是谁 汤梦佳演技怎么样
-
阴阳师云冥界哪里多 夏之泡影任务答案触发方法介绍
-
福原爱女儿嫩照曝光宝宝叫什么名字 江宏杰笑称发量最像自己
-
崔雪莉开直播自曝只穿内裤?与郑秀晶不和撕逼事件怎么回事
-
唐嫣罗晋已分手原因是什么?同拍一场戏互动甚少是吵架了吗
-
46岁董卿现身会议显疲惫!腰椎疼痛走路缓慢,头发凌乱衬衫褶皱多
-
接连离巢!TVB新闻首席主播悄然离巢,结束6年新闻主播生涯
-
51岁咏梅罕晒近况!穿着朴素扎俏皮丸子头,发际线高额角秃一块
-
好莱坞72岁女星新作赤身出镜遭小李子反对,导演:最后用了替身
-
巨石再次确认不回归《速激10》,叫板范老大:别再消费保罗·沃克
-
年度终极盘点!2021年近70位明星翻车:8人违法乱纪,4人隐婚隐育
-
66岁陈道明给青年演员讲话!称干这行少染毛病,一众大牌立正鞠躬
-
去陌生人家里拍摄是一种什么样的体验?这部日综太暖了!
-
张庭、林瑞阳人生中的3次“暗度陈仓”
-
赵丽颖晒照优雅迷人似少女,认真研读剧本受期待,力破发福传闻
-
张小斐张译荣获金鸡奖影后影帝,于和伟张子枫落选,刘浩存陪跑
-
当年的人们为什么沉迷“小品”
-
前瞻|14台“跨晚”火拼!台网平台年度终极一战,谁能跨出新气象?
-
演员孙俪:大女主光环之外的世界丨抉择2021
-
涂松岩谈起儿子激动落泪!41岁得子把他宠上天,连保姆都不想请
-
跨年晚会超十档,央卫视进行大比拼
-
15岁黄多多染发后首晒自拍!穿白衬衫涂大红唇,眼神犀利变化太大
-
朱媛媛获金鸡奖最佳女配!贫嘴张大民的媳妇,在事业巅峰曾拒演潜伏
-
成为蜘蛛侠意味着什么?《蜘蛛侠:英雄无归》核心探讨
-
王牌部队:9年前的娘娘腔,如今变硬汉团长,肖战“与狼共舞”了
-
74岁施瓦辛格和妻子完成离婚!25年婚姻正式完结,离婚用了10年
-
8.3分爆火,它拍出了聪明女人恋爱该有的样子
-
37岁男星自曝移居国外!已跟妻子及宠物在日本隔离,强调不是移民
-
王宝强与张子枫吃饭,对她超宠溺,弟弟去世成他一生遗憾
-
刘雪华人生太难了,被刘德凯辜负丈夫坠楼身亡,如今独居不愿出门
-
金星发文质问江苏卫视!镜头海报都被剪,11月就有人爆料没法播
-
当年齐名刘德华前程似锦,却花样作死自断星途,如今活成笑话还想翻红?
-
孙红雷悼念恩师梁伯龙,此前还亲去探病,后者曾培养出巩俐陈宝国
-
千万网红白冰惹争议!用公共食材进餐,商家未更换继续使用
-
张庭夫妇的明星朋友圈
-
拍照不离场,镜头前摔跤,模仿名人翻车,明星红毯抢戏“心机”多
-
知名男星吃蘑菇被紧急送医,曾因 成功 追星杨幂笑到下巴脱臼
-
又有一档宝藏综艺上线,全网四五星好评!网友评价:一看就上头
-
李到晛、高旻示三搭!《五月的青春》的悲剧能否改写?
-
正面刚!金星开撕江苏卫视,怒斥节目组把她P掉,连接出事疑遭封杀
-
《误杀2》,满身盔甲,目光狰狞,只不过是要保护那个想保护的人
-
巩俐恩师梁伯龙举办告别仪式,夏雨等学生送花圈,外甥女发文悼念
-
退休养老?赵本山卸任辽宁民间艺术团有限公司法人、董事长等职务
-
子瑜美貌引热议,令韩网疯狂;刘在石再获大赏,共计18次!
-
送女儿出国留学被骂!女星礼貌回应网友,承诺孩子将来会回馈祖国
-
小品王高秀敏墓:雕像是谢幕专用动作,碑上仅有出生年份意义特殊
-
著名演员王子文:14岁辍学,29岁走红,未婚生子,生父成谜
-
两拒天王,事业巅峰时因病退隐,做护士的李绮红现在怎么样了?
-
老戏骨高雄被曝私下爱骂不敬业演员,从来都有话直说,不怕得罪人
-
网友喊话林俊杰冷暴力!曾被初恋误会没钱,追田馥甄却和金莎暧昧
-
黄磊和刘若英有了“第四种感情”后,孙莉毫不介意?
-
林瑞阳前妻发文庆祝女儿生日,网友齐齐刷屏:大仇得报
-
“国民妹妹”00后张子枫,获金鸡奖提名,她的星途让人刮目相看
-
《李茂扮太子》预售过千万 马丽常远与你“美丽常伴”
-
《李茂扮太子》预售过千万 马丽常远与你“美丽常伴”
-
《小虎墩大英雄》曝角色海报 与超萌虎娃齐闹新春
-
《小虎墩大英雄》曝角色海报 与超萌虎娃齐闹新春
-
《风起洛阳》刘梦珂精彩演绎“圣人首席大助”焕相boss
-
宋茜《风起洛阳》会员收官 BE结局赚足观众眼泪
-
宋茜《风起洛阳》会员收官 BE结局赚足观众眼泪
-
《扑通扑通的水球少年》开机 王皓轩演绎天才少年白浪
-
《扑通扑通的水球少年》开机 王皓轩演绎天才少年白浪
-
陈依琪《输赢》高情商卖鞋 神操作攻破辛芷蕾
-
陈依琪《输赢》高情商卖鞋 神操作攻破辛芷蕾
-
《向着明亮那方》扎根中国故事 超越年龄限制的“童年宝藏”
-
《爱情神话》十大彩蛋首度揭秘 塑造人间烟火
-
《爱情神话》十大彩蛋首度揭秘 塑造人间烟火
-
《风起洛阳》结局大快人心?实则有3大漏洞,留下3大未解谜团
-
从兄妹相称到夫妻,结婚后仅维持两年,玖月奇迹离婚早就有预兆了
-
唱得少钱却平分,被调侃赚钱最容易的男歌手,曾毅到底会不会唱歌
-
王大陆蔡卓宜复合了?两人街头牵手散步,将女友搂入怀中难掩甜蜜
-
今年的日影十佳,得有它的名字
-
神剧就是神剧,一回归又是9.8分
-
《人世间》亮相 雷佳音辛柏青宋佳演绎百姓奋斗史
-
《汪汪队立大功大电影》角色海报曝光 期待贝贝表现
-
热依扎短发造型曝光 旗袍显清丽古典美
-
热依扎短发造型曝光 旗袍显清丽古典美
-
关晓彤大片来袭 黑色亮片裙性感美丽
-
关晓彤大片来袭 黑色亮片裙性感美丽
-
爱情电影《好想去你的世界爱你》周依然施柏宇约定情人节
-
爱情电影《好想去你的世界爱你》周依然施柏宇约定情人节
-
《东北虎》定档 章宇马丽中年夫妻遭遇婚姻危机
-
《东北虎》定档 章宇马丽中年夫妻遭遇婚姻危机
-
王嘉尔开年封 嘎嘎野得性感又纯粹
-
王嘉尔开年封 嘎嘎野得性感又纯粹
-
苗侨伟《飞虎3》再演“阿sir” 期待有突破自己的机会
-
苗侨伟《飞虎3》再演“阿sir” 期待有突破自己的机会
-
《断·桥》官宣端午档 马思纯、王俊凯、范伟主演
-
《断·桥》官宣端午档 马思纯、王俊凯、范伟主演
-
《狙击手》张译三度合作张艺谋 大年初一上映
-
《狙击手》张译三度合作张艺谋 大年初一上映
-
《李茂扮太子》北京首映 马丽常远魔性走位舞嗨翻全场
-
《李茂扮太子》北京首映 马丽常远魔性走位舞嗨翻全场
-
《东北虎》官宣定档 映照生活中的荒诞与无奈
-
杨幂陈伟霆《斛珠夫人》 格局“添彩”融大义国风增色
-
杨幂陈伟霆《斛珠夫人》 格局“添彩”融大义国风增色
-
《幸福二重奏》殷桃孙艺洲揭秘“高婚商”幸福之道
-
《幸福二重奏》殷桃孙艺洲揭秘“高婚商”幸福之道
-
《雪中悍刀行》的几个亿究竟花哪了?宣传营销上?
-
《雪中悍刀行》的几个亿究竟花哪了?宣传营销上?
-
《输赢》:对手变爱人 情感陷入传统套路
-
被嫌弃的雄狮少年的一生
-
抄郭敬明抄成收视第一,这也行
-
《爱情神话》上映5天票房未过亿,新人导演邵艺辉:一切为了自己能拍
-
跨年晚会上的“打工人”:3位参加3场,周深堪称“娱乐圈劳模”
-
《小敏家》李萍引起热议,女性真正强大的样子,是实力和底气
-
曹云金前妻骨折仍不忘晒娃!3岁女儿长相精致,被夸赞像混血娃娃
-
梁靖琪挺大孕肚与老公为儿子庆生 佘诗曼汤盈盈等七魔女齐聚参加
-
TVB女星又少一个,26岁赵慧奈高调离巢,曾与刘銮雄42岁长子相恋
-
近10届金鸡奖的9个“遗憾”:刘德华错过影帝,有人6次提名皆失手
-
张庭事件升级:17亿总部大楼面临危机!律师和官媒给出说法
-
前央视主播张宏民罕现身,退休多年样子没变,圈粉70多万要做直播
-
TVB男艺人林子善携妻为女儿庆祝2岁生日 一家三口去游乐场游玩庆祝
-
给力,3部电影冲进影史票房榜
-
辱华滥用语境下该学迪斯尼吗?把玲娜贝儿整成了大眼睛
-
《蜘蛛侠:英雄无归》全球票房超74亿 打破索尼影业最高纪录
-
相声界又痛失名家,著名表演艺术家耿殿生去世,6月份还登台演出
-
梅艳芳逝世18周年,袁咏仪深夜晒照问候,连续第11年悼念梅姐
-
年度最佳国产爱情剧?也就过家家的水平吧︱三九专栏
-
为什么大家都想要《爱很美味》宋超的联系方式?
-
陈乔恩携男友参加派对,和Alan搞怪比丑,偶像包袱全无
-
脱口秀演员船长因病去世,好友20余天前去病房探望,已非常虚弱
-
37岁钟嘉欣偶遇谢天华!笑容满面毫无皱纹,亲密搭肩感情好
-
《雪中悍刀行》第14位美女登场,李纯饰演的轩辕青锋,不负众望!
-
第34届金马奖上,刘若英为何当众羞辱张国荣?
-
宋祖儿为毛晓彤新电影包场,三丽四美模仿海绵宝宝派大星拍照超可爱
-
24年了,《快乐大本营》正式告别,新节目曝光!
-
女星对直角肩好执着!鞠婧祎用力到发抖,赵露思秒变直角肩
-
快乐大本营无声告别,是你的青春吗?
-
杨紫分享日常的小幸福,拼乐高、扮cos、吃美食,满满当当看着就充实
-
金鸡电影节最佳女主是谁?最佳影片哪部?最佳男主是谁:排名来了!
-
国产武侠剧,不应该没落下去
-
《你好星期六》细节曝光,挥别谢娜维嘉,何炅重组五人主持团队
-
快乐大本营都停播了,2022年综艺的路该往哪走?
-
《蜘蛛侠:英雄无归》4K蓝光碟封面公开 发售日待定!
-
2021,特别漫长
-
与朱单伟离婚刚半月,陈亚男三次带货捞金,评分暴跌恐无法再直播
-
八一厂山东选角演《苦菜花》,看了一圈,导演:演田嫂的演员呢?
-
剧透+双标?鹿晗这次算是被《五哈》节目组坑惨了
-
42岁陈乔恩被指暴瘦变脸,她懒理争议晒新发型,可爱卖萌笑容超甜
-
李若彤追星成功!晒与视后邓萃雯合照,激动发文:终于有了张合照
-
张馨予穿睡衣聚餐!单腿上炕坐姿像大佬,吃地瓜烫得直叫还吐出来
-
曾黎,为什么还不红?
-
开年争议之作,不止女性复仇爽片那么简单
-
豆瓣开分5.8,什么年代了,还在玩玛丽苏大女主?
-
专访三只松鼠模特:你可以不喜欢,但是不能诋毁
-
女心理师小文扮演者是谁 汤梦佳演技怎么样
-
查杰女朋友是谁他是哪里人 曾参演《刺客列传》
-
风起洛阳永川郡主扮演者是谁?是幕后隐藏大头领
-
陈廷嘉跟谁像?曾参演《大汉天子3》
-
迟帅的妻子是谁?妻子为一名影视演员
-
蔡蝶结婚了吗?曾客串参演《爱情公寓第一季》
-
陈彦妃结婚了吗?老公为一名圈外人
-
程媛媛的老公是谁?参演《红楼梦》平儿出道
-
华晨宇怎么会看上樊博艺呢 恋爱是真的?
-
吴谨言黄景瑜是什么关系 合作拍摄《青春创世纪》
-
陈维涵的老公是谁?出演过《姐妹新娘》《我叫刘跃进》等
-
徐璐前男友有哪些?因张铭恩出轨分手
-
曹磊的妻子是谁?毕业于中央戏剧学院表演系音乐剧班
-
白翔女朋友是谁?出演过《择天记》《全职高手》等
-
成泰燊的妻子是谁?出演过《海鲜》《世界》《玉战士》等
-
崔航的老婆是谁?出演过《四千金》《不能错过》等
-
陈菲结婚了吗?自小学习芭蕾舞和音乐
-
陈昊的女朋友是谁 出演过什么电视剧
-
程怡的老公是谁 演过《刘三姐》《幸运兔精灵》等
-
徐璐文咏珊什么关系 一起演过电视剧《风声》
-
演员许凯的所有影视作品 《招摇》《烈火军校》等
-
凭“九百九十九朵玫瑰”爆火,被李宗盛看不起,邰正宵如今怎样了
-
舒畅:5岁出道,15岁走红,当年多风光,如今多‘拉胯’
-
内地7位2婚女明星,各有各的苦衷,最大46岁,最小28岁
-
凭《涛声依旧》爆红,与杨钰莹传绯闻,毛宁为何突然“销声匿迹了”?
-
张庭和林瑞阳,从婚姻到生意,他们光鲜亮丽背后藏着的故事更精彩
-
45岁林心如晒封面大片,罕见穿露脐装秀身材,马甲线超吸睛
-
张庭关闭评论!8年40位明星为其推广产品,翻车了集体闭口不言
-
黎瑞恩送18岁女儿出国留学,机场紧紧相拥显不舍,母女长相太相似
-
央视八套新剧《超越》定档!胡军沙溢做配角,女主是李庚希
-
爆哭!贾玲一出场,又是年度大爆款
-
张庭夫妇公司陷传销风波,涉案金额巨大,陶虹也是股东
-
一手好牌打得稀烂,原本可以大红大紫非要自毁前程,如今落魄不堪
-
澳门明星有哪些?梁洛施离开豪门成为女强人,“天王嫂”升级当妈
-
鹿希派吸毒后现身道歉,获吴宗宪拥抱力挺,不会退圈希望继续做音乐
-
41岁谢霆锋现身小餐馆!翘二郎腿打扮似路人,同粉丝合影手插兜
-
“草莽枭雄”柯俊雄,横跨港台影坛、政界的传奇人生
-
“人间清流”张豆豆:因“挺胸照”爆红,宁做体操教练不入娱乐圈
-
说人“长相辱华”,可真是年度笑话
-
《爱情神话》热映中 马伊琍吴越倪虹洁金句不断
-
《爱情神话》热映中 马伊琍吴越倪虹洁金句不断
-
《李茂扮太子》爆笑幕后花絮 常远艾伦笑场不停玩嗨了
-
《李茂扮太子》爆笑幕后花絮 常远艾伦笑场不停玩嗨了
-
《今天的她们》杀青 宋轶、佘诗曼领衔主演
-
《今天的她们》杀青 宋轶、佘诗曼领衔主演
-
《问天》热播 凌潇肃何雨晴献唱主题曲《飞过》
-
《问天》热播 凌潇肃何雨晴献唱主题曲《飞过》
-
黄轩《风起洛阳》收官 角色把控力和可塑性获赞
-
黄轩《风起洛阳》收官 角色把控力和可塑性获赞
-
《输赢》热播 陈坤辛芷蕾共守行业底线
-
《输赢》热播 陈坤辛芷蕾共守行业底线
-
刘恩佳《风起洛阳》收官 心地善良却误入歧途
-
刘恩佳《风起洛阳》收官 心地善良却误入歧途
-
王一博状告黑粉案胜诉 登载致歉声明赔偿15000元
-
王一博状告黑粉案胜诉 登载致歉声明赔偿15000元
-
周迅代言品牌线上发布 薰衣草紫薄纱长裙尽显好气色